After five years at Meta and three years building Shaped, I think relevance infrastructure should work like a database: declarative, composable, and fast enough for humans and agents.
These experiences are not optional for consumers. They are critical for business survival. At Meta, experiments comparing AI-driven ranking against chronological feeds sometimes delivered an 800% increase in engagement. That is not a margin tweak. It is a product-changing result. Features, and sometimes entire startups, live or die on that kind of lift.
That is why I left FAIR to build Shaped: to make the infrastructure behind those results available to every product team, not just the largest platforms.
The path through the noise
Relevance is valuable everywhere, but it is existential in some places. An e-commerce store with twenty SKUs does not need a complex engine. A marketplace with ten thousand listings does. Algorithmically surfacing the right product is the difference between a purchase and a bounce.
When we started Shaped in 2021, the industry was shifting. TikTok had made the “For You” feed the default mental model for discovery. E-commerce teams still needed robust recommendations, but feed infrastructure was the wedge where patterns had not yet solidified. We focused there first and saw customers get 120% engagement lifts and double-digit conversion improvements.
The Frankenstein problem
Over time we expanded into email optimization, cart cross-sells, “what to watch next,” and search. Historically, search and recommendations were treated as separate disciplines: Elastic for keyword retrieval, Python stacks or vector databases for recommendations. That split no longer makes sense. Ranking logic that understands user intent improves search. Semantic retrieval improves recommendations. Maintaining two stacks for essentially the same math is expensive.
By early 2025 we had explored most discovery use cases. Then we hit a different wall: API complexity. To make every digital surface intelligent, integration has to be effortless. Whether a team sees a 5% lift or an 800% lift, the cost of finding out must be near zero.
We had added so many use cases that our API had become a patchwork of implicit configurations. It worked when our solutions engineers were in the loop. It was not declarative enough for self-serve. That interface was holding us back.
Agents changed the interface
At the same time, how software gets built changed. I went from writing most of my code to having LLMs write most of it. Our customers started asking for agent retrieval (RAG). The relevance engine that powers search today is the context engine that will power agents tomorrow.
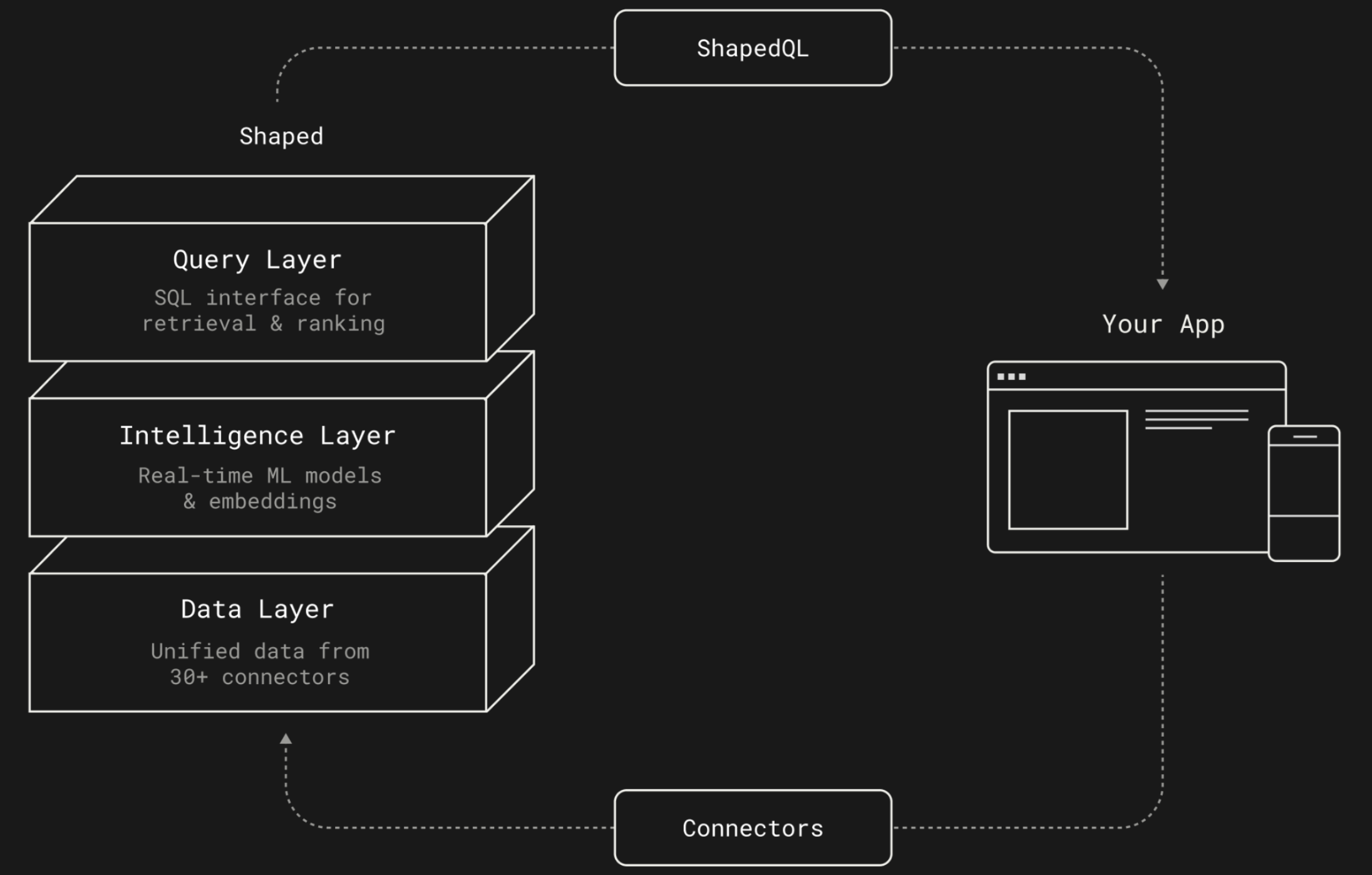
That pushed us toward a new API that is easy for humans to read and easy for LLMs to call: explicit, SQL-shaped, and composable. We shipped that as Shaped 2.0.
Relevance as a database
Think of it less like a recommendation widget and more like a database for relevance.
Building state-of-the-art discovery used to mean stitching together:
- Vector databases for retrieval, without the ranking logic business goals require
- Search engines for keywords, without semantic understanding or personalization
- Feature stores for real-time user signals
Shaped 2.0 collapses that stack. You insert users, items, and interaction events. Shaped indexes semantic representations, computes cross-features, and trains models on a schedule you declare. On top, a SQL-like query language composes multi-stage pipelines: retrieve, filter, score, reorder.
Hybrid search might look like this:
SELECT title, description
FROM
semantic_search("$param.query"),
keyword_search("$param.query")
ORDER BY
colbert_v2(item, "$param.query") +
click_through_rate_model(user, item)That single syntax maps search, feed ranking, and agent retrieval. Configuration stays in version-controlled YAML so relevance logic gets the same review process as application code.
Garbage in, garbage out
We have seen every messy data stack imaginable. Ingestion is not enough. Teams need transforms that clean and unify catalog and event data before models see it. AI-assisted enrichment can impute missing tags or normalize descriptions so models get a complete view of users and inventory.
What I think comes next
Building Shaped has been humbling. The last decade is littered with failed recommendation startups. Most were too vertical or too abstract. We tried to walk the line: prove value in one wedge, expand deliberately, and follow where customers pull us.
The next user is not only human. Agents will query product catalogs, documentation, and marketplaces on behalf of people. If your relevance engine cannot serve those queries with low latency and fresh signals, you become invisible.
I want one engine that serves both: the discovery experiences humans scroll through today, and the retrieval APIs agents will depend on tomorrow. That is the bet behind Shaped 2.0, and the broader reason I keep working on this problem.