If you’ve ever tried to take a promising machine learning experiment from an offline notebook to a live A/B test, you know the pain. Weeks, sometimes months, pass between proving an idea works and actually seeing it in front of users. Internal handoffs, infrastructure gaps, and competing priorities all slow you down. And by the time your experiment goes live, the opportunity may have shifted, or worse, been shelved altogether. At Shaped, we’ve been thinking deeply about this “research-to-production gap” and how to eliminate it for recommendation systems. Here’s what we’ve learned.
The Many Flavors of Experiments
When companies talk about “experimentation” they often mean very different things. In recommendation systems, we typically see experiments fall into these categories:

- New Use Cases - Expanding beyond your homepage to, say, category pages or similar-item carousels.
- New Objectives - Shifting optimization from pure conversion to repeat purchases, average order value, or engagement.
- New Data Types or Sources - Moving from product data to content data, or from Amplitude events to Segment events.
- New Features - Creating derived data points (e.g., is weekend from a timestamp) to feed into models.
- New Models or Model Categories - Tweaking an existing model’s parameters vs. adopting an entirely new architecture.
Each of these comes with a different scope and cost in time, infrastructure, and cross-team collaboration.
Two Worlds: Offline vs. Online
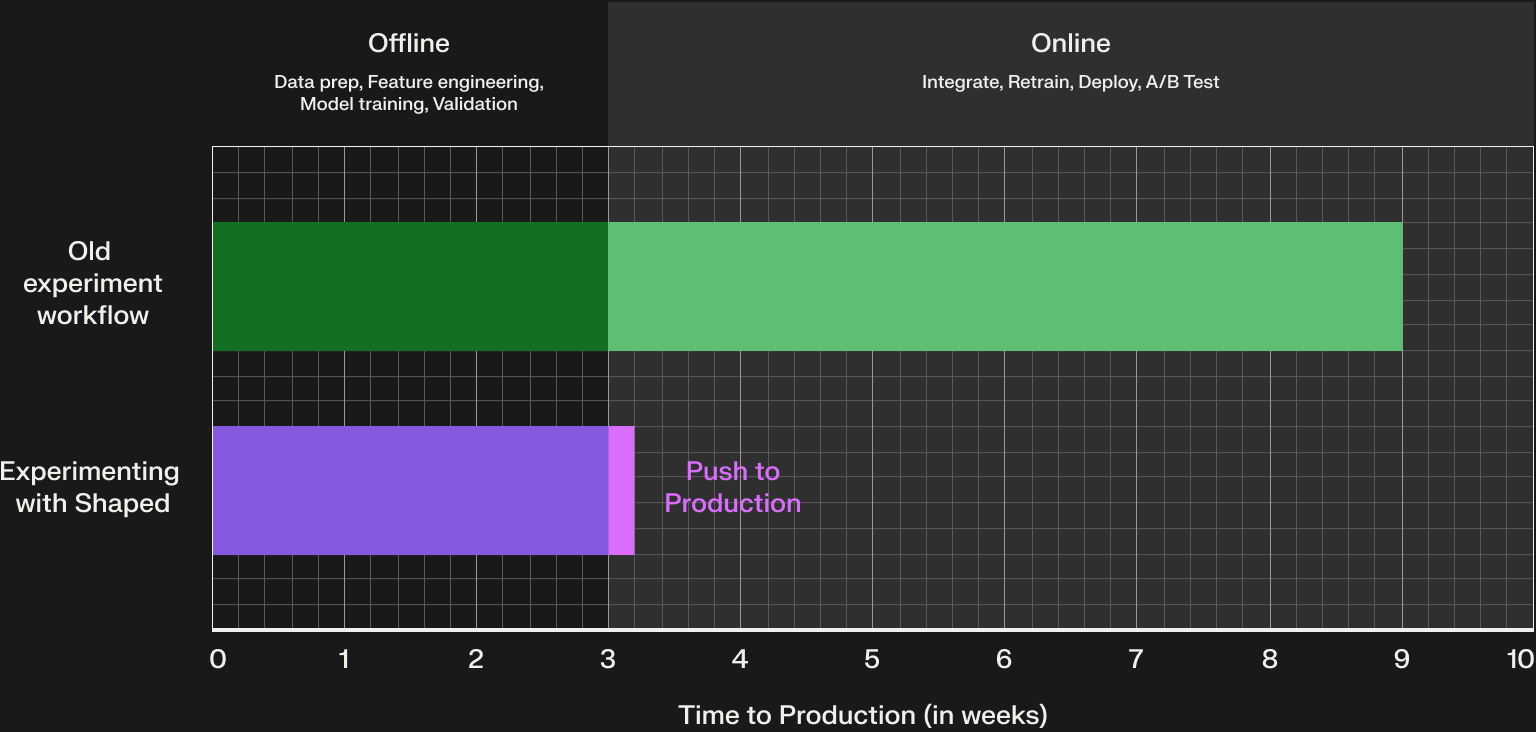
Most experimentation workflows have two major phases:
1. Offline experimentation This is your proving ground, running the model on historical data to see if it outperforms the current production system. You’ll split your dataset into training and validation sets, evaluate performance, and compare multiple candidate ideas. This phase might take 2-3 weeks, and it’s often exploratory and enjoyable for data scientists.
2. Online experimentation Here’s where the fun stops for many teams. Moving an offline win into production can require:
- Feature store integration
- Model retraining and redeployment
- Infrastructure changes for new model categories
- Setting up and running an A/B test
This can take anywhere from a few weeks to over a year, depending on complexity and maturity of your stack.
And this is where most of the slowdown happens.
The Research-to-Production Gap
Industry research estimates that 80% of ML projects never make it to production. The reason? The research-to-production gap, the messy, political, and resource-intensive work of translating an offline model into a live experiment.
This gap often means teams only promote their top three experiments out of dozens of promising ones. Valuable ideas get left behind, not because they didn’t work, but because pushing them live was too costly.
Why It Matters
For product managers, this means strategic objectives like increase repeat purchase rate can translate into live experiments in weeks, not quarters. For ML engineers, it means you don’t have to watch your best ideas languish in a backlog. For leadership, it means a faster path to measurable business impact from your recommendation investments.
Key takeaways
- Most recommendation teams don’t fail on modeling; they fail on experiment velocity and production parity.
- Offline metrics only matter when they predict online outcomes under real latency and data constraints.
- Shared feature pipelines, golden tests, and fast rollback beat hero models that never ship.